If you are producing digital content, you already know the biggest problem with AI voice generators: they sound flat. Even the best models struggle to capture the natural pauses, breaths, and emotional shifts that a real human actor brings to a script.
In April 2026, Google completely changed the landscape by releasing Gemini Flash 3.1 TTS (Text-to-Speech). This is not just an update to make voices sound slightly clearer. It is an entirely new framework that gives you granular, “director-level” control over how an AI speaks.
Table of Contents
Whether you are building localized virtual influencers, producing high-end AI commercials, or developing interactive voice agents, here is exactly why this model is trending and how you can use it.
What is Gemini Flash 3.1 TTS?
Gemini 3.1 Flash TTS is a dedicated text-to-speech model built by Google. Unlike general language models, it is optimized specifically for audio output quality and prosody (the rhythm and intonation of speech).
The model supports over 70 languages and regional variants, featuring 30 highly curated prebuilt voices. While other platforms focus heavily on voice cloning, Google has chosen a different route: offering a massive library of high-fidelity, highly controllable baseline voices that you can mold into custom personas.
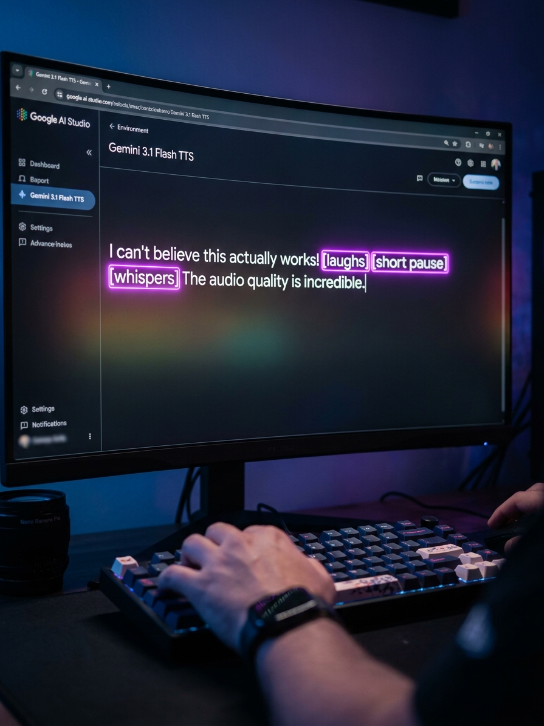
The Game Changer: “Inline Audio Tags”
The absolute best feature of Gemini Flash 3.1 TTS is how it allows you to direct the AI. Most tools require you to select an “angry” or “happy” voice profile, which forces the AI to speak the entire script with that one emotion.
Gemini 3.1 Flash TTS uses Inline Audio Tags. You can embed commands directly into your text prompt inside square brackets [ ] to change the emotion or add non-verbal sounds mid-sentence.
Here is how it looks in practice:
“[excitedly] We just launched the new platform! [short pause] [whispers] But don’t tell the competition yet. [laughs]”
The AI will actually transition from shouting with excitement, to taking a breath, dropping to a whisper, and ending with a realistic chuckle. You have access to over 200 tags, including [nervousness], [frustration], [hope], [long pause], and [sighs].
Why This is Massive for AI Commercials & Virtual Influencers
If you are running an agency focused on high-end creative marketing and AI personas, this level of control solves your biggest production bottlenecks.

- Perfecting the Virtual Influencer Persona: A high-fidelity visual avatar is useless if the voice sounds like a robotic customer service bot. By using Gemini 3.1 Flash TTS, you can lock in a specific “Audio Profile.” You can tell the model: “You are an energetic, 25-year-old fashion influencer from Casablanca.” The model uses this context, along with your inline tags, to generate a consistently branded, culturally accurate voice performance across hundreds of videos.
- Complex Commercial Narratives: Cinematic AI commercials require dynamic voiceovers. If an ad transitions from a high-energy hook to a calm, reassuring product breakdown, you no longer need to generate multiple audio files and stitch them together in post-production. You can script the entire commercial in one prompt using pacing tags like
[fast]or[slow]to let the dramatic moments land. - Global Localization at Scale: With support for 70+ languages, you can take a highly expressive voiceover script that worked perfectly in English and translate it directly into French or Arabic, while keeping the exact same emotional tags
[laughs]and[short pause]intact.
Pricing and How to Access It
Google has made Gemini Flash 3.1 TTS incredibly accessible and highly cost-effective for developers and creators.
- Where to find it: You can test the model for free right now in the Google AI Studio playground. Simply select “Text to Speech” from the output options, choose
gemini-3.1-flash-tts-preview, and start typing with your inline tags. - The Cost: For API users scaling commercial applications, the pricing is highly aggressive: roughly $2 per 1 million input tokens, and just $0.04 per 1,000 output tokens.
- Safety First: To combat misinformation, Google natively embeds an imperceptible “SynthID” watermark into all audio generated by the model, ensuring the content is always identifiable as AI-generated.
The Verdict
Gemini Flash 3.1 TTS bridges the gap between robotic synthesis and genuine human performance. By simply typing a few bracketed tags, creators now have access to a virtual recording studio, allowing for scalable, high-fidelity audio production that previously required expensive human talent.